Test statistic mathematics¶
Often in machine learning, we want to compare the performance of different models to determine if one statistically outperforms another. However, the methods used (e.g., data resampling, k-fold cross-validation) to obtain these performance metrics (e.g., classification accuracy) violate the assumptions of traditional statistical tests such as a t-test. The purpose of these methods is to either aid generalisability of findings (i.e., through quantification of error as they produce multiple values for each model instead of just one) or to optimise model hyperparameters. This makes them invaluable, but unusable with traditional tests, as Dietterich (1998) found that the standard t-test underestimates the variance, therefore driving a high Type I error. correctipy is a lightweight package that implements a small number of corrected test statistics for cases when samples are not independent (and therefore are correlated), such as in the case of resampling, k-fold cross-validation, and repeated k-fold cross-validation. These corrections were all originally proposed by Nadeau and Bengio (2003). Currently, only cases where two models are to be compared are supported.
correctipy is a lightweight package that implements a small number of corrected test statistics for cases when samples of two machine learning model metrics (e.g., classification accuracy) are not independent (and therefore are correlated), such as in the case of resampling and k-fold cross-validation. We demonstrate the basic functionality here using some trivial examples for the following corrected tests that are currently implemented in correctipy:
Random subsampling
k-fold cross-validation
Repeated k-fold cross-validation
These corrections were all originally proposed by Nadeau and Bengio (2003) with additional representations in Bouckaert and Frank (2004).
Random subsampling correction¶
In random subsampling, the standard t-test inflates Type I error when used in conjunction with random subsampling due to an underestimation of the variance, as found by Dietterich (1998). Nadeau and Bengio (2003) proposed a solution (which we implement as correctipy.resampled_ttest() in correctipy) in the form of:

where n is the number of resamples (NOTE: n is not sample size), n_{1} is the number of samples in the training data, and 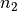 is the number of samples in the test data.
is the number of samples in the test data. sigma^{2} is the variance estimate used in the standard paired t-test.
k-fold cross-validation correction¶
There is an alternate formulation of the random subsampling correction, devised in terms of the unbiased estimator rho, discussed in Corani et al. (2016) which we implement as correctipy.kfold_tttest() in correctipy:

where n is the number of resamples and rho = 1/k where k is the number of folds in the k-fold cross-validation procedure. This formulation stems from the fact that Nadeau and Bengio (2003) proved there is no unbiased estimator, but it can be approximated with rho = 1/k.
Repeated k-fold cross-validation correction¶
Repeated k-fold cross-validation is more complex than the previous case(s) as we now have r repeats for every fold k. Bouckaert and Frank (2004) present a nice representation of the corrected test for this case which we implement as correctipy.repkfold_ttest() in correctipy:
